In pharma manufacturing, batch rejects are often treated mainly as a quality issue.
A batch fails. QA investigates. The deviation is documented. Corrective actions are discussed. Temporary containment is implemented. The plant moves on.
But after a few weeks or months, the same type of rejection appears again.
This is where many pharma plants need to pause and ask a difficult question:
Are we only detecting the reject, or are we eliminating the operating condition that created it?
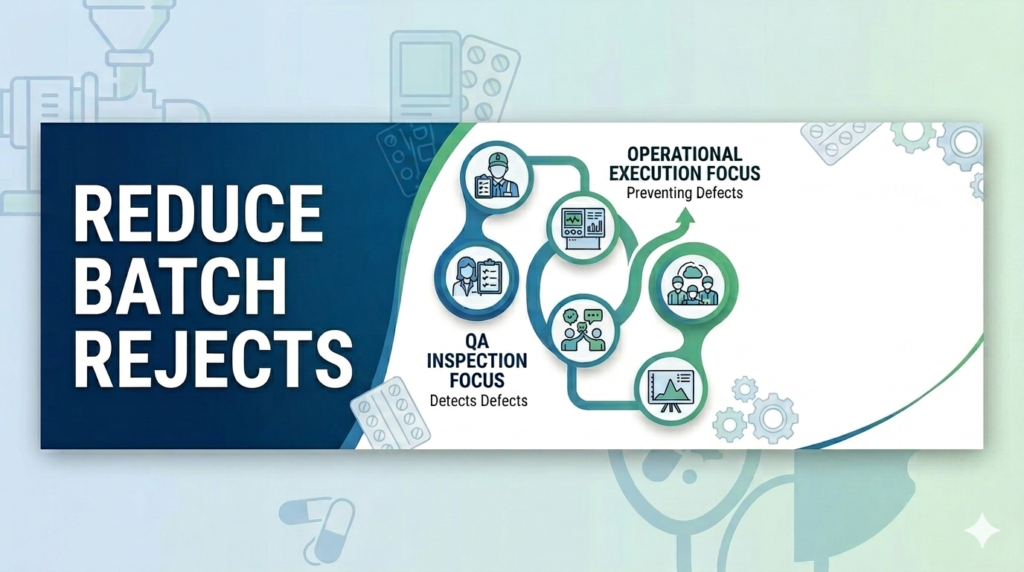
In many cases, recurring batch rejects are not only quality failures. They are execution failures on the shop floor.
The inspection process detects the defect.
The shop floor often creates it.
And if the execution gap is not removed, the same losses continue silently inside normal operations.

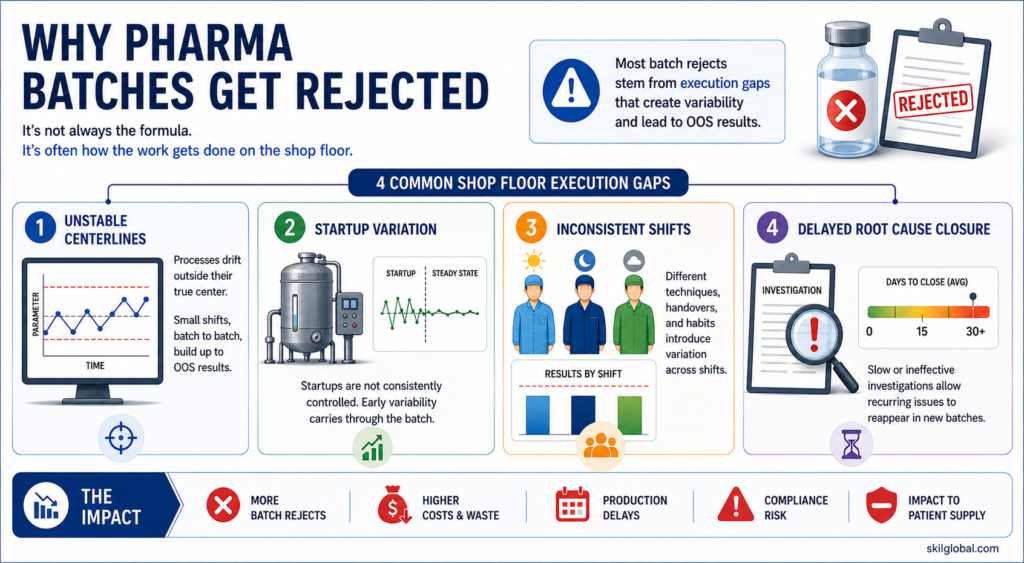
Batch Rejects Are Often Symptoms of Operational Instability
A recurring batch rejection rarely starts at the final inspection stage.
It usually starts much earlier.
It may begin with a small drift in machine centerline settings.
It may come from an unstable startup after product changeover.
It may come from variation in critical process parameters between shifts.
It may come from a worn-out component that was not detected early enough.
It may come from weak handover between production, maintenance, and quality teams.
It may come from operators adjusting the process differently based on experience.
By the time QA identifies the problem, the operational loss has already happened.
This is why adding more inspection or more QA checks may reduce immediate risk, but it does not always reduce the root cause of rejection.
Containment is necessary.
But containment is not improvement.
The Wrong Approach: Treating Every Reject as Only a QA Problem
Many pharma plants respond to rejects through a quality-heavy approach.
The typical cycle looks like this:
- Batch is rejected.
- QA investigation begins.
- Temporary containment is applied.
- The plant resumes production.
- Similar loss appears again later.
This approach may satisfy immediate investigation requirements, but it often fails to remove the shop-floor cause.
The real issue may be inside:
- Machine setting variation
- Changeover instability
- Startup weakness
- Poor equipment condition
- Parameter drift
- Inconsistent shift practices
- Delayed escalation
- Weak preventive maintenance
- Ineffective CAPA closure
When these issues are not addressed at the operating level, rejects keep returning.
The cost is not limited to rejected material. The plant also loses productive capacity, machine time, manpower hours, QA investigation time, testing resources, delivery reliability, and margins.
The Sustainable Solution: Shift from QA Focus to Execution Focus
Plants that consistently improve First Pass Yield do not rely only on investigation after failure.
They build daily operational discipline before failure.
A strong reject reduction program focuses on stabilizing the process at the source.
This requires cross-functional ownership between production, quality, maintenance, engineering, and operational excellence teams.
The objective is not to blame the shop floor.
The objective is to make the process more stable, more visible, and more controlled.
Five Execution Controls That Help Reduce Pharma Batch Rejects
1. Stable Machine Centerline Settings
Machine centerlines define the best-known operating condition for a product, batch, or process.
When these settings are not clearly defined, controlled, and verified, operators may run the same process differently across shifts.
This creates variation.
A good centerline system should define:
- Critical machine settings
- Acceptable operating range
- Product-wise setup parameters
- Changeover setting requirements
- Verification responsibility
- Escalation rule when settings drift
Centerline control helps convert operator-dependent performance into process-dependent performance.

2. Startup Verification After Changeover
Many rejects are created during startup after a product changeover, batch change, cleaning activity, or line clearance.
The first few minutes or first few cycles after startup are critical.
If the machine is not stabilized before full production, the plant may produce defects before anyone notices.
Startup verification should include:
- Correct machine setup confirmation
- Parameter verification
- Trial run checks
- First-piece or first-output approval
- Quality checkpoint confirmation
- Maintenance readiness check
- Operator sign-off
- QA or production approval where required
The goal is simple:
Do not allow unstable startup conditions to enter full-scale production.

3. Cross-Functional Ownership
Batch rejects are rarely owned by one function alone.
Production may control execution.
Quality may control approval and investigation.
Maintenance may control machine condition.
Engineering may control process capability.
OpEx may control improvement discipline.
If each function works separately, the root cause remains fragmented.
A stronger approach is to create cross-functional ownership around recurring reject themes.
For example:
| Reject Cause | Production Role | Quality Role | Maintenance Role | OpEx Role |
| Parameter variation | Follow and record standard settings | Verify compliance and trend deviations | Check sensor/equipment condition | Drive root cause closure |
| Startup instability | Execute startup checklist | Approve critical checks | Confirm machine readiness | Monitor recurrence |
| Equipment wear | Report abnormalities early | Review impact on quality | Prevent recurrence through PM | Track benefit and sustainment |
Reject reduction becomes faster when ownership is shared and visible.

4. Process Consistency Across Shifts
One of the most common hidden causes of batch variation is shift-to-shift inconsistency.
Shift A may run the process one way.
Shift B may adjust settings differently.
Shift C may not receive the full handover of abnormalities.
This creates unstable execution.
To improve consistency, plants should strengthen:
- Shift handover checklists
- Standard work verification
- Visual parameter boards
- Abnormality logs
- Operator skill matrix
- Supervisor Gemba checks
- Daily review of shift-wise variation
If the same product behaves differently in different shifts, the problem is not only technical.
It is also a management system problem.

5. Faster Root Cause Closure on the Shop Floor
Many plants complete investigations, but the same problems repeat because root cause closure is slow or superficial.
A strong reject reduction system should separate temporary correction from permanent corrective action.
For example:
Temporary correction: Hold the batch, inspect additional samples, adjust the machine.
Permanent corrective action: Fix the setting standard, replace worn component, update startup checklist, train operators, add verification control, audit compliance.
Root cause closure must happen close to the Gemba, where the process actually runs.
Useful tools include:
- Pareto analysis
- 5 Why analysis
- Fishbone diagram
- Process parameter trend review
- FMEA update
- CAPA effectiveness check
- Layered process audit
- Daily management review
The speed of learning matters.
The faster the plant converts a reject into a permanent control, the faster FPY improves.

Hidden Losses Are Often Buried Inside “Normal Operations”
In many manufacturing diagnostics, the biggest losses are not always visible in monthly reports.
They are hidden inside accepted routines.
Examples include:
- Operators making repeated small adjustments
- Minor stoppages not recorded
- Startup delays treated as normal
- Machine drift accepted until failure
- Shift handover gaps ignored
- Rework treated as part of production
- QA waiting time not measured as capacity loss
- Preventive maintenance checks completed on paper but not effective in practice
These losses silently reduce yield, capacity, delivery reliability, and profitability.
That is why reject reduction must be treated as an operational efficiency program, not only a quality improvement project.

A Practical 90-Day Approach to Reduce Pharma Batch Rejects
A focused reject reduction program can begin with a 90-day execution roadmap.
First 30 Days: Diagnose the Loss
- Identify top reject categories
- Build Pareto by product, line, batch, defect type, shift, and machine
- Validate FPY baseline
- Review deviation recurrence
- Map process parameters
- Identify high-risk changeover and startup points
- Estimate cost of poor quality
Next 30 Days: Attack the Root Causes
- Stabilize machine centerlines
- Implement startup verification controls
- Strengthen shift handovers
- Close recurring CAPA actions
- Improve maintenance response to wear-related defects
- Train operators on critical process controls
- Conduct weekly Gemba-based reviews
Final 30 Days: Lock the Gains
- Update SOPs and control plans
- Add layered process audits
- Create daily management routines
- Track FPY improvement
- Validate reduction in recurring rejects
- Review CAPA effectiveness
- Hand over ownership to line leadership
The purpose is not only to reduce one defect.
The purpose is to build a system that prevents recurrence.

Final Thought
Reducing batch rejects in pharma is not only about stronger QA inspection.
It is about stronger process execution.
Inspection can detect the defect.
Investigation can explain the failure.
But operational discipline prevents recurrence.
The plants that consistently improve FPY build control around stable centerlines, startup verification, cross-functional ownership, shift consistency, and faster root cause closure.
That is where real operational efficiency begins.

Question for Plant Leaders and OpEx Teams
What is the hardest part of sustaining machine centerlines after a major product changeover in your plant?
Is it operator discipline, unclear standards, equipment condition, shift variation, QA approval delay, or lack of daily follow-up?

Call to Action
If your plant is facing recurring batch rejects, unstable FPY, high rework, or repeated deviation trends, it may be time to look beyond inspection and diagnose the real execution gaps.
Book a 45-minute Pharma Reject Reduction Diagnostic Call with SKIL Global Business Solutions.
In this call, we will help you identify your top reject contributors, review your current FPY and deviation trends, estimate hidden operational losses, and outline a practical 90 to 120-day improvement roadmap.
Stop treating recurring rejects as isolated quality events. Start treating them as operational losses that can be measured, controlled, and reduced.



